JavaScript系列之执行上下文和执行栈
如果你想成为一名优秀的 JavaScript 开发者,那你就必须了解 JavaScript 程序内部的执行机制。而执行上下文和执行栈是其关键概念之一, 理解执行上下文和执行栈同样有助于理解其他的 JavaScript 概念如提升机制、作用域和闭包等。
执行上下文和执行栈是 JavaScript 的难点之一,所以本人尽量用通俗易懂的方式来阐述这些概念。
执行上下文(Execution Context) #
当 JavaScript 代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。执行上下文(可执行代码段)总共有三种类型:
- 全局执行上下文(全局代码):不在任何函数中的代码都位于全局执行上下文中,只有一个,浏览器中的全局对象就是
window对象,this指向这个全局对象。 - 函数执行上下文(函数体):只有调用函数时,才会为该函数创建一个新的执行上下文,可以存在无数个,每当一个新的执行上下文被创-建,它都会按照特定的顺序执行一系列步骤。
Eval函数执行上下文(eval 代码): 指的是运行在eval函数中的代码,很少用而且不建议使用。
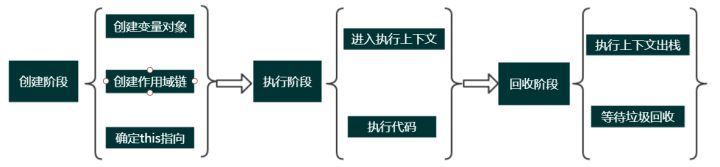
执行上下文又包括三个生命周期阶段:创建阶段 → 执行阶段 → 回收阶段,本文重点介绍创建阶段。
1.创建阶段
当函数被调用,但未执行任何其内部代码之前,会做以下三件事:
- 创建变量对象(Variable object,VO):首先初始化函数的参数
arguments,提升函数声明和变量声明。后文会详细说明。 - 创建作用域链(Scope Chain:在执行上下文的创建阶段,作用域链是在变量对象之后创建的。作用域链本身包含变量对象。作用域链用于解析变量。当被要求解析变量时,JavaScript 始终从代码嵌套的最内层开始,如果最内层没有找到变量,就会跳转到上一层父作用域中查找,直到找到该变量。后文会详细说明。
- 确定 this 指向:包括多种情况,后文会详细说明。
在一段 JS 脚本执行之前,要先解析代码(所以说 JS 是解释执行的脚本语言),解析的时候会先创建一个全局执行上下文环境,先把代码中即将执行的变量、函数声明都拿出来。变量先暂时赋值为undefined,函数则先声明好可使用。这一步做完了,然后再开始正式执行程序。
另外,一个函数在被执行之前,也会创建一个函数执行上下文环境,跟全局上下文差不多,不过函数执行上下文中会多出this 、 arguments和函数的参数。
2.执行阶段
进入执行上下文、执行代码
3.回收阶段
执行完毕后执行上下文出栈并等待被垃圾回收
执行上下文栈(Execution Context Stack) #
假如我们写的函数多了,每次调用函数时都创建一个新的执行上下文,如何管理创建的那么多执行上下文呢?
所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文,具有 LIFO(后进先出)的栈结构,用于存储在代码执行期间创建的所有执行上下文。
首次运行 JS 代码时,会创建一个全局执行上下文并 Push 到当前的执行栈中。每当发生函数调用,引擎都会为该函数创建一个新的函数执行上下文并 Push 到当前执行栈的顶部,浏览器的 JS 执行引擎总是访问栈顶的执行上下文。
根据执行栈 LIFO 规则,当栈顶函数运行完成后,其对应的函数执行上下文将会从执行栈中 Pop 出,上下文控制权将移到当前执行栈的下一个执行上下文,最终移回到全局执行上下文,全局上下文只有唯一的一个,它在浏览器关闭时 Pop 出。
看到目前为止,是否觉得这两个概念还是有点晦涩难懂呢?那…接下来通过几小段代码和图解来详细介绍并理解吧。
执行上下文是如何执行的呢? #
让我们先来看一下这段简单代码:
function b() {}
function a() {
b();
}
a();
这段代码背后执行的逻辑是这样的:
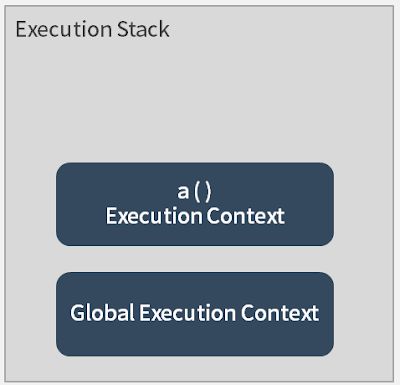
首先,全局执行上下文(Global Execution Context)会被建立,这时候会一并建立this、global object (window),在函数开始执行的过程中,function a和b由于 JS 提升机制的缘故会先被建立在内存中,接着才会开始逐行执行函数。

接着,代码会执行到a( )这个部分,这时候,会建立a的执行上下文(execution context),并且被放置到执行栈(execution stack)中。在这个 execution stack 中,最上面的 execution context 会是正在被执行的a( )。如下图:
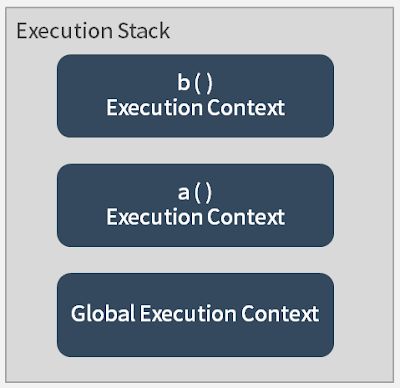
function a 的 execution context 建立后,便会开始执行function a中的内容。由于在function a( ) 里面有去执行function b ,因此,在这个 execution stack 中,接下来最上面会变成function b 的 execution context。如下图:
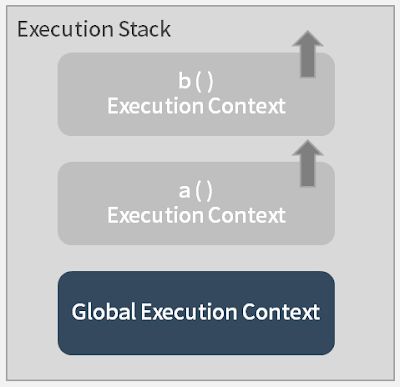
当function b 执行完之后,会从 execution stack 中离开,继续逐行执行function a。当function a 执行完之后,一样会从 execution stack 中抽离,再回到 Global Execution Context 逐行执行。如下图:
不同执行上下文中的变量是不同的 #
在了解了一般的函数其运作背后的逻辑后,让我们来看一下这段代码:
function b() {
var myVar;
console.log(myVar);
}
function a() {
var myVar = 2;
b();
console.log(myVar);
}
var myVar = 1;
console.log(myVar);
a();
你可以想像,如果我们在不同的 execution context 中去把myVar这个变量打出来,会得到什么结果呢?结果如下:

我们分别得到了 1、undefined和 2。为什么会这样呢?
让我们来看看这段代码背后执行的逻辑:
首先,全局执行上下文(Global Execution Context)会被建立,由于变量提升的缘故,myVar、function a和b都会被建立并储存在内存中,接着便开始逐行执行函数。一开始会碰到var myVar = 1所以,最外层的myVar便被给值为 1,接着执行到了console.log(myVar),这是在 global execution context 执行的,于是得到了第一个 1 的结果:

然后执行到了a ( ),于是建立了a的 execution context,这时候由于逐行执行的关系,会先执行到var myVar = 2,但因为这是在 function a 的 execution context 中,所以并不会影响到 global execution context 的myVar:
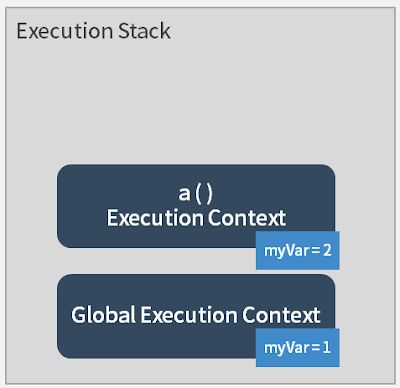
在执行完function a中的var myVar = 2后,继续逐行执行,于是执行到了b ( ),这时候,function b的 execution function 便被建立,而且会先去执行function b里面的内容:
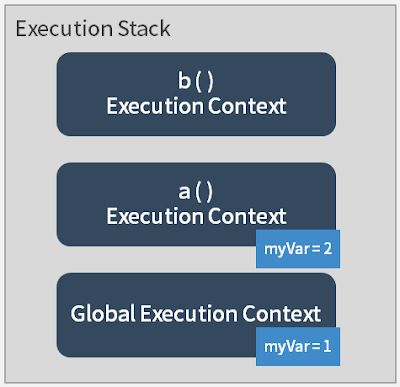
function b的 execution function 建立后,会开始逐行执行function b里面的内容,于是读到了var myVar;,这时候在function b这个 execution context 中的myVar变量被建立,但是还没被赋值,所以会是undefined。和上面提到的一样,由于这个myVar是在function b中的 execution context 所建立,所以并不会影响到其他 execution context 的myVar,这时候执行到了function b的 execution context 中的console.log(myVar),于是得到了第二个看到的undefined:
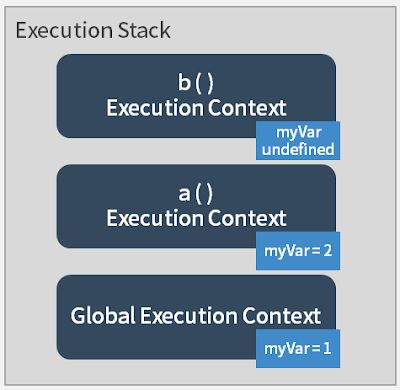
最后,function b执行完之后,会从 execution stack 中离开,继续回到function a中的b( )后逐行执行,也就是console.log(myVar),这时候是在 function a 的 execution context 加以执行的,因此也就得到了结果中看到的第三个 2 了。
最后由于b ( ) 后面已经没有内容,function a执行完毕,这时候,function a也会从 execution stack 中抽离。
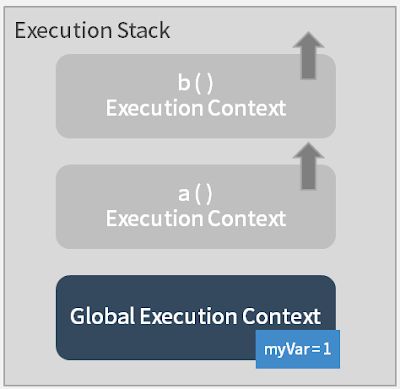
最后回到 Global Execution Context,如果函数中的a( )后面还有内容的话,会继续进行逐行执行。
由上面的例子,我们可以知道,我们是在不同的 execution context 中分别去声明变量myVar的,因此在不同的 execution context,变量彼此之间不会影响,所以虽然这三个变量都叫做myVar,但其实是三个不同的变量。
由于我们是在不同的 execution context 中去声明变量,所以这其实是位于三个不同 execution context 中的变量,所以即使我们是在执行完a( )后再去调用一次myVar,一样会得到" 1"的结果:
function b() {
var myVar;
console.log(myVar);
}
function a() {
var myVar = 2;
b();
console.log(myVar);
}
var myVar = 1;
console.log(myVar);
a();
console.log(myVar); // 一样会得到"1"
注意 #
最后需要注意的是,如果是在function里面直接使用myVar这个变量,而没有通过var重新声明它的话,就会得到不同的结果!因为在函数作用域内加 var 定义的变量是局部变量,不加 var 定义的就成了全局变量。在未声明新的变量的情况下,在该 execution context 中 JavaScript 引擎找不到这个变量,它就会往它的外层去寻找,最后会得到,1 ,2 ,2 ,2 的结果:
function b() {
myVar;
console.log(myVar);
}
function a() {
myVar = 2;
b();
console.log(myVar);
}
var myVar = 1;
console.log(myVar);
a();
console.log(myVar);
/*
打印出
1
2
2
2
*/
如果觉得文章对你有些许帮助,欢迎在我的 GitHub 博客点赞和关注,感激不尽!